ベクトル化の(ほぼ)サポート
近頃、LLM や AI などに関する話題で非常ににぎわっています。 ベクトルデータベースもそれなりに関わっており、IRIS 以外では、世界中で多様なサポートがすでに実現されています。
なぜベクトルなのでしょうか?
- 類似検索: ベクトルでは、データベース内で最も類似する項目やドキュメントを検索するなど、効率的な類似検索が可能です。 従来のリレーショナルデータベースは完全一致検索向けに設計されているため、画像やテキストの類似検索といったタスクには向いていません。
- 柔軟性: ベクトル表現には汎用性があり、テキスト(Word2Vec、BERT などの埋め込み経由)や画像(ディープラーニングモデル経由)などの様々なデータタイプから導き出すことができます。
- クロスモーダル検索: ベクトルでは、様々なデータモダリティでの検索が可能です。 たとえば、画像のベクトル表現を基に、マルチモーダルデータベースで類似する画像や関連するテキストを検索できます。
理由は他にも多数あります。
そこで、この Python コンテストでは、このサポートを実装してみることにしました。 残念ながら時間内に完成させることはできませんでしたが、その理由を以下で説明します。
 完全にするには、やらなければならない主な項目がいくつかあります。
完全にするには、やらなければならない主な項目がいくつかあります。
- ベクトル化データを SQL で受け入れて格納する。以下は単純な例です(この例の「3」は次元数であり、フィールドごとに固定されており、そのフィールドのすべてのベクトルにこの正確な次元が必要です)。
createtable items(embedding vector(3)); insertinto items (embedding) values ('[1,2,3]'); insertinto items (embedding) values ('[4,5,6]'); - 類似関数。類似には様々なアルゴリズムがあり、インデックスを使用しない少量のデータでの単純な検索に適しています。
-- ユークリッド距離select embedding, vector.l2_distance(embedding, '[9,8,7]') distance from items orderby distance; -- コサイン類似度select embedding, vector.cosine_distance(embedding, '[9,8,7]') distance from items orderby distance; -- 内積select embedding, -vector.inner_product(embedding, '[9,8,7]') distance from items orderby distance; - カスタムインデックス。大量のデータでのより高速な検索に役立ちます。インデックスには異なるアルゴリズム、上記の異なる距離関数、およびその他のオプションを使用できます。
- HNSW
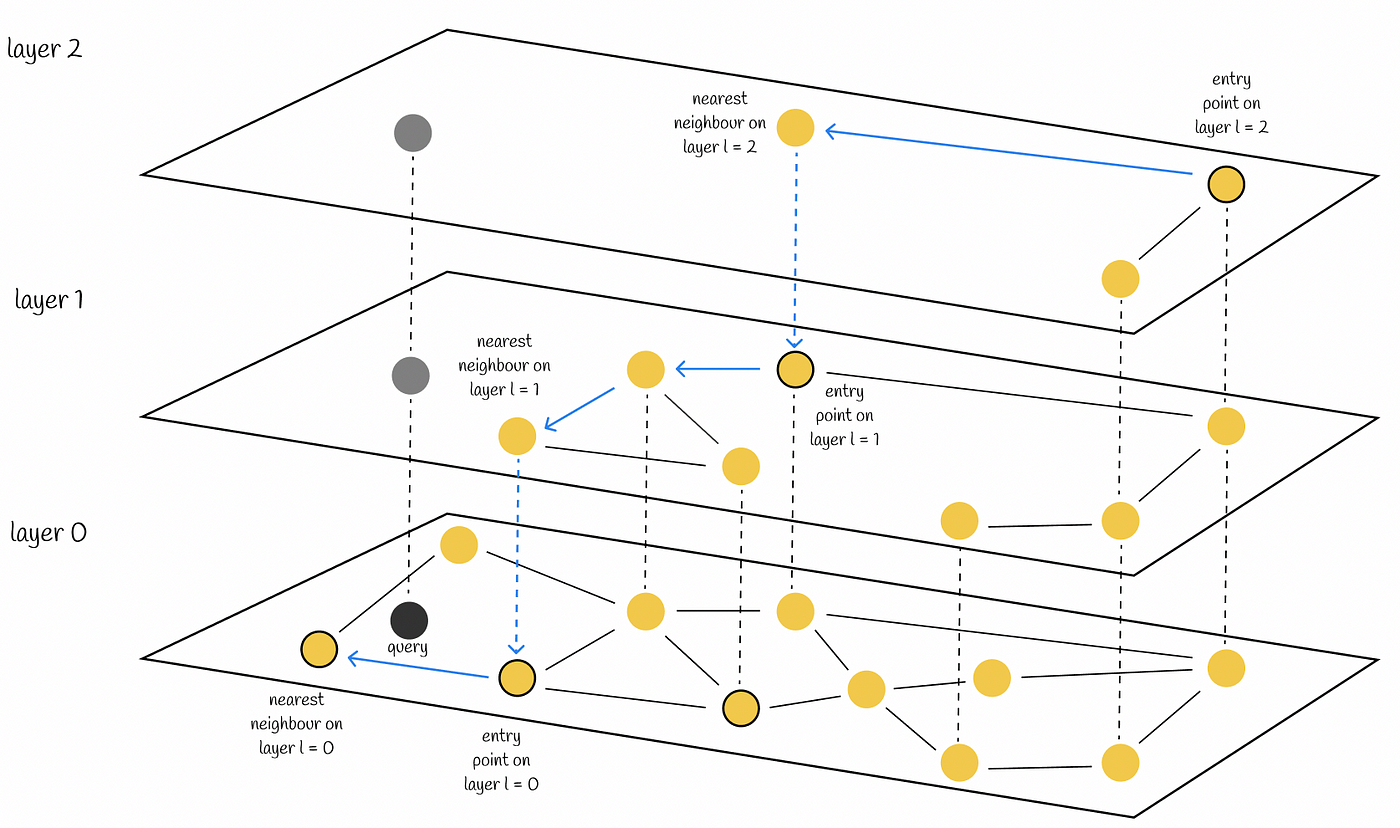
- 転置ファイルインデックス
.png)
- HNSW
- 検索は作成されたインデックスを使用し、そのアルゴリズムによってリクエストされた情報が検索されます。
ベクトルの挿入
ベクトルは、整数や浮動小数点数のほかに、符号付きや符号なしの数値の配列であることが期待されています。 IRIS では、それを単に $listbuild として格納できます。これには最適な表現があり、すでにサポートされているため、ODBC から論理への変換のみを実装する必要があります。
すると、ODBC/JDBC などの外部ドライバーを使って、または IRIS 内では ObjectScript を使って、プレーンテキストとして値を挿入できます。
- プレーンな SQL を使用
insertinto items (embedding) values ('[1,2,3]'); - ObjectScript を使用
set rs = ##class(%SQL.Statement).%ExecDirect(, "insert into test.items (embedding) values ('[1,2,3]')")set rs = ##class(%SQL.Statement).%ExecDirect(, "insert into test.items (embedding) values (?)", $listbuild(2,3,4))
- または埋め込み SQL を使用
&sql(insertinto test.items (embedding) values ('[1,2,3]'))set val = $listbuild(2,3,4) &sql(insertinto test.items (embedding) values (:val))
必ず $lb() として格納され、ODBC でテキスト形式で戻されます。
その後、JDBC はデフォルトで高速挿入を使用しており、その場合、挿入されたデータを直接 globals に格納することがわかったため、その機能を手動でオフにする必要がありました。
DBeaver では、FeatureOption フィールドの optfastSelect を選択してください。
.png)
計算
ベクトルは主に、2 つのベクトルの間の距離の計算をサポートするために必要です。
コンテストにおいては、Embedded Python を使用する必要がありました。問題はここからです。Embedded Python で $lb をどのように操作するのか。%SYS.Class には ToList メソッドがありますが、Python パッケージは iris にビルトインされていないため、ObjectScript のやり方が必要となります。
ClassMethod l2DistancePy(v1 As dc.vector.type, v2 As dc.vector.type) As%Decimal(SCALE=10) [ Language = python, SqlName = l2_distance_py, SqlProc ]
{
import iris
import math
vector_type = iris.cls('dc.vector.type')
v1 = iris.cls('<span class="hljs-built_in">%SYS.Python</span>').ToList(vector_type.Normalize(v1))
v2 = iris.cls('<span class="hljs-built_in">%SYS.Python</span>').ToList(vector_type.Normalize(v2))
<span class="hljs-keyword">return</span> math.sqrt(sum([(val1 - val2) ** <span class="hljs-number">2</span> <span class="hljs-keyword">for</span> val1, val2 in zip(v1, v2)]))
}
まったく正しいようには見えません。 $lb は Python でその場でリストとして、または少なくともビルトイン関数の o_list と from_list として解釈されるのが好ましいと思います。
もう 1 つの問題は、この関数を様々な方法でテストしようとしたときにありました。 Embedded Python で記述された SQL を 使用する SQL を Embedded Python から使用すると、クラッシュします。 そこで、ObjectScript の関数も追加する必要がありました。
ModuleNotFoundError: No module named 'dc' SQL Function VECTOR.NORM_PY failed with error: SQLCODE=-400,%msg=ERROR #5002: ObjectScript error: <OBJECT DISPATCH>%0AmBm3l0tudf^%sqlcq.USER.cls37.1 *python object not found
距離を計算するために現在実装されている関数(Python と ObjectScript の両方)
- ユークリッド距離
[SQL]_system@localhost:USER> select embedding, vector.l2_distance_py(embedding, '[9,8,7]') distance from items orderby distance; +-----------+----------------------+ | embedding | distance | +-----------+----------------------+ | [4,5,6] | 5.91607978309961613 | | [1,2,3] | 10.77032961426900748 | +-----------+----------------------+ 2 rows in setTime: 0.011s [SQL]_system@localhost:USER> select embedding, vector.l2_distance(embedding, '[9,8,7]') distance from items orderby distance; +-----------+----------------------+ | embedding | distance | +-----------+----------------------+ | [4,5,6] | 5.916079783099616045 | | [1,2,3] | 10.77032961426900807 | +-----------+----------------------+ 2 rows in setTime: 0.012s - コサイン類似度
[SQL]_system@localhost:USER> select embedding, vector.cosine_distance(embedding, '[9,8,7]') distance from items orderby distance; +-----------+---------------------+ | embedding | distance | +-----------+---------------------+ | [4,5,6] | .034536677566264152 | | [1,2,3] | .11734101007866331 | +-----------+---------------------+ 2 rows in setTime: 0.034s [SQL]_system@localhost:USER> select embedding, vector.cosine_distance_py(embedding, '[9,8,7]') distance from items orderby distance; +-----------+-----------------------+ | embedding | distance | +-----------+-----------------------+ | [4,5,6] | .03453667756626421781 | | [1,2,3] | .1173410100786632659 | +-----------+-----------------------+ 2 rows in setTime: 0.025s - 内積
[SQL]_system@localhost:USER> select embedding, vector.inner_product_py(embedding, '[9,8,7]') distance from items orderby distance; +-----------+----------+ | embedding | distance | +-----------+----------+ | [1,2,3] | 46 | | [4,5,6] | 118 | +-----------+----------+ 2 rows in setTime: 0.035s [SQL]_system@localhost:USER> select embedding, vector.inner_product(embedding, '[9,8,7]') distance from items orderby distance; +-----------+----------+ | embedding | distance | +-----------+----------+ | [1,2,3] | 46 | | [4,5,6] | 118 | +-----------+----------+ 2 rows in setTime: 0.032s
数学関数(加減乗除)を追加で実装しました。 InterSystems は独自の集計関数の作成をサポートしているため、 すべてのベクトルを合計したり平均を求めることが可能かもしれません。 しかし、残念ながら、InterSystems では同一の名前の使用をサポートしていないため、関数に独自の名前(およびスキーマ)を使用する必要があります。 ただし、集計関数では数値以外の結果はサポートされていません。
2 つのベクトルの合計を返す単純な vector_add 関数
.png)
集計として使用すると、0 を示し、期待されるベクトルも同様に表示されます。
.png)
インデックスの作成
残念ながら、実装中に直面した障害により、この部分は完成させられませんでした。
- IRIS のベクトルが $lb に格納されている場合のビルトイン $lb から Python リストへの変換とその逆変換が不足しており、インデックス作成のすべてのロジックが Python で書かれていることが期待されるため、$lb からデータを取得して globals にも設定することが重要です。
- globals のサポートの欠如
- IRIS の $Order は方向をサポートしているため、逆方向でも使用可能ですが、Python Embedded での順序の実装にはこれが存在しないため、すべてのキーを読み取って順序を逆にするか、最後をどこかに格納する必要があります。
- 上記の Python から呼び出される Python の SQL 関数がうまくいかないため、疑問を感じている
- インデックス作成中、ベクトル間の距離がグラフに格納されることが期待されていたのに、global で浮動小数点数に関するバグが発生した
この作業中に見つかった Embedded Python 関連の課題を 11 件作成しました。ほとんどの時間は問題を解決するための回避策を見つけるのに費されました。 いくつかの問題は、@Guillaume Rongier の iris-dollar-list というプロジェクトのお陰でなんとか解決できました。
インストール
いずれにせよ、これは引き続き提供中であり、IPM でインストールし、機能が制限されていても使用できます。
zpm "install vector"または開発モードでは docker-compose を使用できます。
git clone https://github.com/caretdev/iris-vector.git
cd iris-vector
docker-compose up -d