インスタンスのデータに基づくビジネスインテリジェンスを実装しようと計画中です。 DeepSee を使うには、データベースと環境をどのようにセットアップするのがベストですか?

インスタンスのデータに基づくビジネスインテリジェンスを実装しようと計画中です。 DeepSee を使うには、データベースと環境をどのようにセットアップするのがベストですか?
 以前の記事では Arduino を使い始め、最終的には気象観測所のデータを表示できるようになりました。 この記事ではさらに掘り下げ、InterSystems Caché アプリケーションに対して RFID カードと Arduino を介した認証をセットアップします。
以前の記事では Arduino を使い始め、最終的には気象観測所のデータを表示できるようになりました。 この記事ではさらに掘り下げ、InterSystems Caché アプリケーションに対して RFID カードと Arduino を介した認証をセットアップします。
みなさん、こんにちは。
数日前、SOAP(Web)サービスを使用して、REST に基づく新しいアプリケーション API と同じ認証を使用できるように、既存のレガシーアプリケーションを拡張したい、とお客様から伺いました。 新しいアプリケーションは OAuth2 を使用しているため、課題は明らかでした。SOAP リクエストを含むアクセストークンをどのようにしてサーバーに渡すか、ということです。
Google でしばらく調べてみたところ、SOAP エンベロープにヘッダー要素を追加してから、アクセストークンを検証するために必要なことを Web サービス実装が実行できるようにするのが 1 つの実現方法であることがわかりました。
皆さん、こんにちは。
ストリームデータをデータベースに格納する場合、ファイルなどから読み取る際に漢字コード変換を行い、Unicode形式で%GlobalCharacterStreamに格納されるかと思いますが、時々、バイナリのままで読み込んでしまい、漢字コード変換を行わないといけない状況があるかと思います。
ファイルストリームでしたら%FileCharacterStreamクラスのTranslateTableプロパティに元の漢字コードを指定すれば、以下のようにコード変換しながら読みだすことは可能です。
%Net.SSH.Session クラスを使用すると、SSH を使ってサーバーに接続することができます。 一般的にはSFTP、特に FTP インバウンドアダプタとFTPアウトバウンドアダプタで使用されています。
この記事では、簡単な例を示しながら、このクラスを使用して SSH サーバーに接続する方法、認証のオプションを記述する方法、そして問題が発生した場合のデバッグ方法について説明します。
次は接続を行う例です。
Set SSH = ##class(%Net.SSH.Session).%New()
Set return=SSH.Connect("ftp.intersystems.com")
上記のコードは新しい接続を作成してから、ftp.intersystems.com の SFTP サーバーにデフォルトのポートで接続します。 この時点で、クライアントとサーバーは暗号化アルゴリズムとオプションを選択済みですが、ユーザーはまだログインしていません。
接続したら、認証方法を選択できます。 選択できるメソッドには次の 3 つがあります。
上記はそれぞれ異なる認証方式です。 各方式を簡単に説明します。
前回は GKE サービスを使用して IRIS アプリケーションを Google Cloud 上で起動しました。
また、クラスターを手動で(または gcloud を介して)作成するのは簡単ですが、最新の Infrastructure-as-Code(IaC)手法では、Kubernetesクラスターの説明もコードとしてリポジトリに格納する必要があります。 このコードの記述方法は、IaC に使用されるツールによって決まります。
Google Cloud の場合は複数のオプションが存在し、その中には Deployment Manager と Terraform があります。 どちらが優れているかにつては意見が分かれています。詳細を知りたい場合は、この Reddit のスレッド「Opinions on Terraform vs. Deployment Manager?」と Medium の記事「Comparing GCP Deployment Manager and Terraform」を参照してください。
企業は変化の激しい業界で競争力を維持するため、イノベーションを起こす必要があります。 この製品は企業が迅速かつ安全な意思決定を行い、より正確な将来の実績を目指せるようにします。
ビジネスインテリジェンス(BI)ツールは、企業が試行錯誤に頼ることなくインテリジェントな意思決定を行うのに役立ちます。 このようなインテリジェントな決定は市場で成功するか失敗するかを決定付けます。
Microsoft Power BI は業界をリードするビジネスインテリジェンスツールの 1 つです。 Power BI では数回クリックするだけでマネージャーやアナリストが企業のデータを簡単に探索できます。 これは重要なことです。容易にデータにアクセスして視覚化できれば、それがビジネス上の意思決定に使用される可能性が高くなるからです。

FTP ファイルを Intersystems Caché からダウンロードするメソッドを以下に示します。ご質問がある場合はメッセージをお寄せください。
皆さん、こんにちは。
開発コミュニティでの検索方法について説明します。
開発コミュニティのページで検索される場合は以下の赤枠の虫眼鏡マークをクリックします。.png)
すると、以下のようにテキストボックスのみ浮かび上がりますので、検索したい文字列を入力します。
以下のように入力した文字列をタイトルに含む記事等が一覧表示されますので、見たい記事がありましたら、その記事をクリックします。.png)
無ければ、そのまま「Enter」キーを押下しますと以下のように検索画面が表示され、検索文字列がタイトルに含まれるものだけでなく本文中に含むものも一緒に表示されますので、見たい記事のタイトルをクリックします。
クラス、テーブル、グローバルとその仕組み
InterSystems IRIS を技術的知識を持つ人々に説明する際、私はいつもコアとしてマルチモデル DBMSであることから始めます。
個人的には、それが(DBMSとして)メインの長所であると考えています。 また、データが格納されるのは一度だけです。 ユーザーは単に使用するアクセス API を選択するだけです。
これは短く簡潔なメッセージで、一見すると素晴らしく聞こえます。しかし、実際には intersystems IRIS を使い始めるたユーザーには クラス、テーブル、グローバルはそれぞれどのように関連しているのだろうか? 互いにどのような存在なのだろうか? データは実際にどのように格納されているのだろうか?といった疑問が生じます。
この記事では、これらの疑問に答えながら実際の動きを説明するつもりです。
データを処理するユーザーは多くの場合、処理対象のモデルに偏見を持っています。
InterSystems API Management(IAM)は、IT インフラストラクチャ内の Web ベースの API との間のトラフィックを監視、制御、および管理できる InterSystems IRIS Data Platform の新機能です。 アナウンスを見逃した方は、こちらのリンクを参照してください。 また、IAM の使い方を説明した記事もあります。
この記事では、InterSystems API Management を使用して API の負荷を分散します。
この例では、2 つの InterSystems IRIS インスタンスを使用し、クライアントに /api/atelier REST API を公開したいと思います。
そのようにしたいと思う理由は、次のようにさまざまです。
Prometheus は時系列データの収集に適した監視システムです。
このシステムのインストールと初期構成は比較的簡単です。 このシステムにはデータ視覚化用の PromDashと呼ばれる画像サブシステムが組み込まれていますが、開発者は Grafana と呼ばれる無料のサードパーティ製品を使用することを推奨しています。 Prometheus は多くの要素(ハードウェア、コンテナ、さまざまな DBMS の構成要素)を監視できますが、この記事では Caché インスタンス(正確に言えば Ensemble インスタンスですが、メトリックは Caché からのものになります)の監視に注目したいと思います。 ご興味があれば、このまま読み進めてください。
非常に単純なケースでは、Prometheus と Caché は単一のマシン(Fedora Workstation 24 x86_64)上に存在します。 Caché のバージョンは以下のとおりです。
インストールと構成
こんにちは! この記事は「Prometheus で InterSystems Caché を監視する」の続きになります。 ここでは ^mgstat ツールの動作結果を視覚化する方法を見ていきます。 このツールを使用すると、Caché のパフォーマンス統計、具体的なグローバルとルーチンの呼び出し数(ローカルおよびECP 経由)、書き込みデーモンのキュー長、ディスクに保存されるブロックと読み取られるブロックの数、ECP トラフィックの量などを取得できます。 ^mgstat は(対話的に、またはジョブによって)単独で起動したり、別のパフォーマンス測定ツールである ^pButtons と並行して起動したりできます。
最近行われたディスカッションの中で、Caché ObjectScript における for/while loop のパフォーマンンスが話に出ましたので、意見やベストプラクティスをコミュニティの皆さんと共有したいと思います。 これ自体が基本的なトピックではありますが、他の点では合理的と言える方法のパフォーマンスが意味する内容を見逃してしまうことがよくあります。 つまり、$ListNext を使って$ListBuild リストをイテレートするループ、または $Order を使ってローカル配列をイテレートするループが最も高速な選択肢ということです。
興味深い例として、コンマ区切りの文字列をループするコードについて考えます。
そのようなループをできるだけ手短に書くと、次のようになります。
For i=1:1:$Length(string,",") {
Set piece = $Piece(string,",",i)
//piece を使って何らかの処理を実行する...
}
とても分かりやすいですね。でも、多くのコーディングスタイルガイドラインは次のようなコードを提案するかもしれません。
データベースシステムには非常に特殊なバックアップ要件があり、企業のデプロイメントでは、事前の検討と計画が必要です。 データベースシステムの場合、バックアップソリューションの運用上の目標は、アプリケーションが正常にシャットダウンされた時と同じ状態で、データのコピーを作成することにあります。 アプリケーションの整合性バックアップはこれらの要件を満たし、Cachéは、このレベルのバックアップ整合性を達成するために、外部ソリューションとの統合を容易にする一連のAPIを提供しています。
Caché パターンマッチングと同様に、Caché では正規表現を使ってテキストデータのパターンを特定することができますが、後者の場合はより高い表現力を利用できます。 本記事では正規表現を簡単に紹介し、Caché での活用方法について解説します。 本記事の情報は、主に Jeffrey Friedl 氏著作の「Mastering Regular Expressions (詳説 正規表現)」に加え、もちろん Caché のオンラインドキュメンテーションなど、様々なリソースを基に提供しています。 本記事は正規表現のあらゆる可能性や詳細について解説することを意図したものではありません。 更なる詳細にご興味のある方は、チャプター 5 に記載のソースを参照してください。 オフラインで読む場合は、PDF バージョンをダウンロードしていただけます。
この記事では $Increment 関数と $Sequence 関数を比較します。
まずは、$Increment 関数を聞いたことがないという方のために、その概要を説明いたします。 $Increment は、CachéObjectScript の関数で、引数をアトミックに 1 ずつインクリメントし、結果の値を返します。 $Increment にパラメーターとして渡せるのはグローバル変数ノードとローカル変数ノードのみで、任意の式を渡すことはできません。 $Increment は連続する ID の割り当てに多用されます。 その場合、$Increment のパラメーターにはグローバルノードがよく使用されます。 $Increment を使用するプロセスには確実に任意の ID が割り当てられます。
for i=1:1:10000 {
set Id = $Increment(^Person) ; 新しい ID
set surname = ##class(%PopulateUtils).LastName() ; ランダムなラストネーム
set name = ##class(%PopulateUtils).FirstName() ; ランダムなファーストネーム
set ^Person(Id) = $ListBuild(surname, name)
}
秩序(順序)はだれにとっても必要であるが、皆が同じように秩序(順序)を理解しているわけではない (ファウスト・セルチニャーニ)
免責事項: この記事では、例としてロシア語とキリル文字を使用しますが、英語以外のロケールでCachéを使用するすべての方に関連のある記事です。この記事は主にNLS照合について言及しており、SQL照合とは異なることに注意してください。 SQL照合(SQLUPPER、SQLSTRING、照合なしを意味するEXACT、TRUCATEなど)は、値に明示的に適用される実際の関数であり、その結果はグローバルサブスクリプトに明示的に格納されることがあります。 サブスクリプトに格納されると、これらの値は当然、有効なNLS照合(「SQLおよびNLS照合」)に従うことになります。
開発者コミュニティの皆さん、こんにちは。
再度ここでObjectScript extension for Visual Studio Codeについてお話しできること、ならびに今回、バージョン 1.0 のリリースを発表することに興奮しています!
開発者コミュニティはInterSystems と共に前例のない方法でこの製品を提供するために力を合わせてきました。開発者の生産性に非常に重要なツールというものは、初期の段階からコミュニティによるテスト、フィードバック、ソースコードによって構築されるのは当然のことです。
このリリースのほとんどの機能は 0.9 から存在しており、前のこの投稿でアナウンスされていました。これらの機能はすべて強化され、洗練されました。
InterSystems IRIS 2019.1は公開されてからしばらく経ちますが、気づかれていない可能性のある、JSONの処理の強化機能について説明したいと思います。 最新のアプリケーションを構築する際、特にRESTエンドポイントを操作する際は、JSONをシリアル化形式として扱うことが重要です。
SQL パフォーマンスリソース
SQL のパフォーマンスについて語るとき、最も重要なトピックとして取り上げられるのが「Indices」、「TuneTable」、「Show Plan」の 3 つです。 添付の PDF にはこれらのトピックに関する過去のプレゼン資料が含まれていますので、それぞれの基礎を一度に確認していただけます。 当社のドキュメンテーションでは、これらのトピックの詳細に加え、SQL パフォーマンスの他のトピックについてもカバーしておりますので、下のリンクからお読みください。 eラーニングをご利用いただくと、これらのトピックをもっと深く理解していただけます。 また、開発者コミュニティによる記事の中にも SQL パフォーマンスについて書かれたものが複数ありますので、関連するリンクを下に記載しております。
下に記載する情報には同じ内容が多く含まれています。 SQL パフォーマンスにおける最も重要な要素を以下に紹介します。
 こんにちは!
こんにちは!
この記事では、IRIS から Caché、Ensemble、HealthShare など、InterSystems の製品で使用されるクラスやその構造を理解するのに役立つツールの概要を簡単にまとめています。
つまり、そのツールはクラスやパッケージ全体を視覚化し、クラス間の相対関係を示し、ディベロッパーやチームリーダーに必要な情報をすべて提供してくれるので、わざわざ Studio に移動してコードを調べる必要が省けます。
InterSystems の製品について情報を集めている方からたくさんのプロジェクトをレビューしている方、または単純に InterSystems Technology ソリューションの新機能に興味がある方まで、ObjectScript Class Explorer の概要をぜひお読みください!
InterSystems は、InterSystemsIRIS を新しいリリース方法を採用しようとしています(訳注:2020年現在、このリリース方法が採用されています)。このブログでは、新しいリリースモデルとお客様が予測しておくべきことを説明しています。 この内容は InterSystems IRIS ロードマップセッションの最後に行われた Global Summit で説明し、お客様から多くの肯定的なフィードバックを受け取ったものです。
この新しいモデルでは、次の 2 つのリリースストリームを提供しています。
1)EM と呼ばれる従来と同じ毎年恒例のリリース(拡張メンテナンス)
2)CD(継続的デリバリーを意味する)のタグが付けられ、コンテナ形式でのみ入手可能になる四半期ごとのリリース。
Ansible は Caché とアプリケーションコンポーネントをいかに迅速にデータプラットフォームのベンチマークにデプロイするかという課題を解決するのに役立ちました。 同じツールと方法をテストラボ、トレーニングシステム、開発環境、またはその他の環境の立ち上げも使うことができます。 顧客サイトにアプリケーションをデプロイする場合、デプロイの大部分を自動化し、アプリケーションのベストプラクティス標準に合わせてシステム、Caché、アプリケーションを確実に構成することができます。
CachéとCosFakerを使ったテスト駆動開発の簡単な紹介
読了****目安時間: 6分
皆さん、こんにちは。
私がTDDに初めて出会ったのは約9年前のことです。すぐに夢中になってしまいました。
最近は非常に人気が出てきているようですが、残念ながら多くの企業ではあまり使われていないようです。 また、主に初心者の方ではありますが、一体それがなんであるのか、どのように使うのかといったことさえも知らない開発者もたくさんいます。
この記事は、%UnitTestでTDDを使用する方法を紹介することを目標としています。 ワークフローを示し、私の最初のプロジェクトであったcosFakerの使用方法を説明します。これはCachéを使って作成したものであり、最近になってOpenExchangeにアップロードしたものです。
では、ベルトを締めて出発しましょう。
テスト駆動開発(TDD)は、自動テストが失敗した場合に、開発者に新しいコードの書き方のみを示すプログラミング実践として定義できます。
このメリットに関する記事、講義、講演などは数多く存在しますが、どれもが正しい内容です。
コードはテスト済みで生成されること、過度なエンジニアリングを避けるために定義された要件に、システムが実際に適合していることを確認できること、継続的にフィードバックを得ることが挙げられます。
InterSystems IRIS のクラスクエリ
InterSystems IRIS(および Cache、Ensemble、HealthShare)のクラスクエリは、SQL クエリを のコードから分離する便利なツールです。 このクエリの基本的な機能は、同じ SQL クエリを複数の場所で異なる引数で使用する場合にクエリの本文をクラスクエリとして宣言し、このクエリを名前で呼び出すことでコードの重複を回避できるというものです。 このアプローチは、次のレコードを取得するタスクを開発者が定義するカスタムクエリにも便利です。 興味が湧きましたか? それではこのまま読み進めてください!
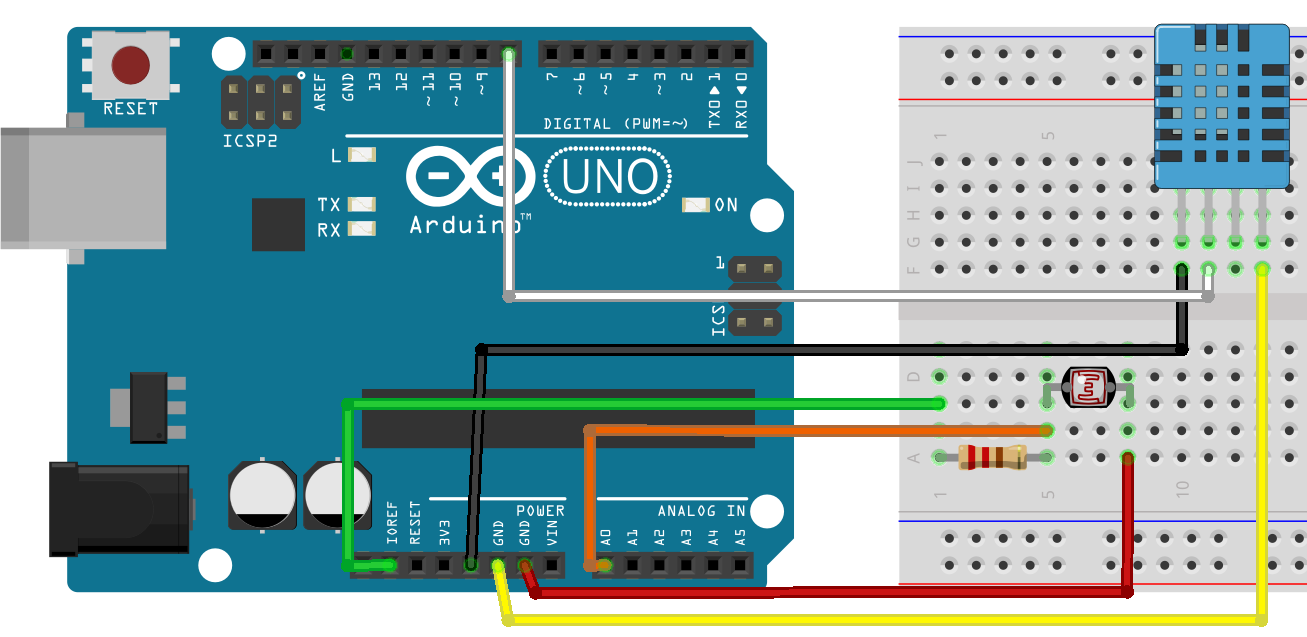
InterSystems ハッカソンの時、Artem Viznyuk と私のチームは Arduino ボード(1 台)とその各種パーツ(大量)を所有していました。 そのため、私たちは活動方針を決めました。どの Arduino 初心者もそうであるように、気象観測所を作ることにしたのです。 ただし、Caché のデータ永続ストレージと DeepSee による視覚化を利用しました!
Amazon Web Services(AWS)クラウドは、コンピューティングリソース、ストレージオプション、ネットワークなどのインフラストラクチャサービスの幅広いセットをユーティリティとしてオンデマンドかつ秒単位の従量課金制で提供しています。 新しいサービスは、先行投資なしで迅速にプロビジョニングできます。 これにより、大企業、新興企業、中小企業、公営企業の顧客は、変化するビジネス要件に迅速に対応するために必要なビルディングブロックにアクセスすることができます。
更新: 2019年10月15日
この記事は、Caché 以前の歴史に関するかなり個人的な見方を書いたものです。
過去の記事で紹介された Mike Kadow 氏の素晴らしい著書に対抗するつもりはありません。
私たちの歴史的背景は異なるため、この記事は過去に対する別の視点を生み出すことを意図しています。
全体的な話は、1966 年に MGH(マサチューセッツ総合病院)で 8K のメモリ(18 ビットワード)[現在 = 18K バイト] を搭載した PDP-7(シリアル番号#103)
が予備のシステムとして使用されたことから始まります。
「シリアル番号 103 は、
現在 [2014] は MGH のコックスがんセンターの敷地になっている取り壊されたセイヤービルの地下にありました。」
「Octo Barnett の指導の下、Neil Papparlardo と Curt Marble が
このマシンで最初のソフトウェアを開発し、リリースしました。」
彼らはこのソフトウェアを MUMPS と名付けました。 (引用元)
PDP-7
言語自体は古い形式の Basic にかなり近いものでした。
しかし、他のプログラミング言語に比べて大幅に改善されている点がありました。
